Using Klusters | |
| Prev | Next |
Table of Contents
To start editing a file, select ->. In the Open dialog, you can select any type of data file (clu, fet, spk, or par: see File Formats).
A session can also be started from the command line, by typing:
%klustersfilename
Once the data is loaded, the main window should look like this:
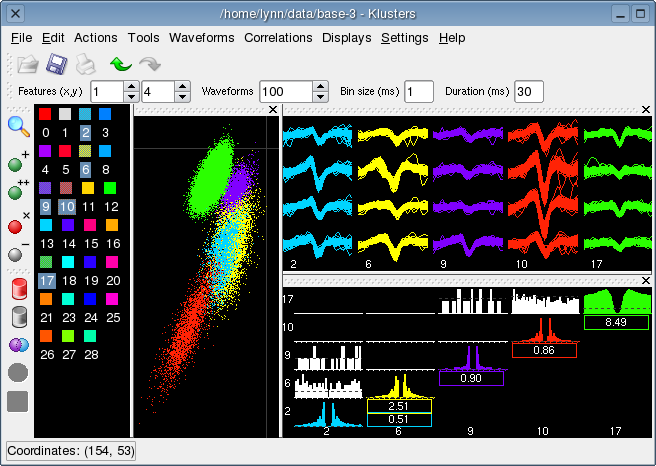
The Cluster Panel (left) lists all the cluster IDs already defined in the cluster file. Clusters can be selected by clicking on the colored squares. Use Shift or CTRL for multiple selections (see the menu for more choices).
The rest of the Main Window shows an Overview Display of the data. This is one of several kinds of display that Klusters uses to present the data. It actually combines three views: a Cluster View displaying spikes in the PCA feature space (left), a Waveform View (top right), and a Correlation View displaying auto- and cross-correlograms (bottom right).
Notice that each cluster has its own color: the same color is consistently used in the Cluster Panel, the Cluster View, the Waveform View, and the Correlation View. This makes it easy to quickly identify a given cluster across different views. If you wish to change the color of a cluster (e.g. when simultaneously displaying several clusters with similar colors), middle-click on the corresponding colored square in the Cluster Panel to open the Color Chooser. As soon as you validate your new choice, all views will be updated accordingly (but see Using Klusters over a Slow Network Connection).
Keep in mind that working on large files requires a large amount of RAM and a powerful CPU.
| Prev | Home | Next |
| Introduction | Up | Views and Displays |